SQL Server Indexes (Clustered Indexes)
When you execute any query in SQL Server, it fetches records in two ways
a) Table Scan
b) Index Lookup
Table Scan – As name suggests when you search for any particular record in the table, the DB Engine has to touch each and individual record till it finds the requested value, this is known as table scan. When the size of table is very large the table scan may perform badly.
Index Lookup – When there is index defined on the table then index lookup will happen on the table. This index lookup returns results efficiently than table scan. One or more number of indexes can be added to one table. There are various types of indexes in SQL Server as below
1. Clustered Indexes
2. Non-Clustered Indexes etc.,
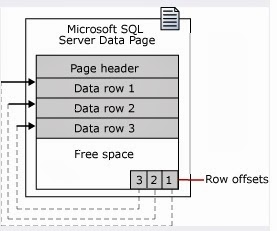
Clustered Index -- Clustered Index will change the physical order of the table, it arrange records in sorted order on the column on which you defined clustered Index, hence we can define only ONE clustered index per table. It has one row in sys.partitions table with IndexId = 1. A cluster index can contain multiple columns hence we call it as composite index.
The database uses B-Tree structure to organize the indexes; it has different types of nodes.
1) Root Node - Always root node will be one, which contains pointers to other nodes.
2) Branch Nodes / Intermediate nodes – Two or more branch nodes, It contains pointers to other branch nodes or leaf nodes
3) Leaf Nodes - A leaf node contains index items and horizontal points to other leaf nodes.
Indexes are organized as B-Trees, Each page in an index B-Tree is called a index node. The root and intermediate pages contains index pages holding index rows. Each index row will contain a key value and a pointer to either an intermediate page or a data row in the leaf level of the index.
The leaf node of clustered index will contain actual data rows. While searching a clustered index field the query engine will fetch records very fast.
Clustered Index Considerations
These are particularly useful while using relational operators such as =,<>,>,<,between, exists etc.,
Also it gives good performance when you use order by and group by clauses.
While defining clustered indexed we need to choose a column in such a way that it should have
many distinct values and unique values.
Defining clustered index are not advised on column that are frequently updated, because update
potentially require re-ordering of the table data and it may cause page splits.
Non-Clustered Indexes
Like clustered index non-clustered index also follows B-Tree structure with few differences, the leaf node of non-clustered index doesn’t store data rows, and data is not stored in sorted order only index rows will be in sorted order. The leaf nodes of non-clustered index contain the non- clustered index key values and each key value has entry pointer to the data row that contains the key value. The pointer from index row in non-clustered index to data row is called row locator. A row locator structure is depends on whether it points to clustered index or to a heap. In simple words the data is stored in one place and index is stored in other place and will have pointers to the storage location of the data. Hence table can have more than one non-clustered index.
If the table is heap which doesn’t have clustered index the row locator points to the row.
If the table has clustered index then row locator refers to cluster index key.
Non-Clustered index has one row in sys.partitions table with IndexID>1
Prior to 2008 SQL Server can have 249 non clustered indexes per table and from 2008 onwards 999 clustered indexes can be created.
Unique constraint will create a non-clustered index by default.
When you execute any query in SQL Server, it fetches records in two ways
a) Table Scan
b) Index Lookup
Table Scan – As name suggests when you search for any particular record in the table, the DB Engine has to touch each and individual record till it finds the requested value, this is known as table scan. When the size of table is very large the table scan may perform badly.
Index Lookup – When there is index defined on the table then index lookup will happen on the table. This index lookup returns results efficiently than table scan. One or more number of indexes can be added to one table. There are various types of indexes in SQL Server as below
1. Clustered Indexes
2. Non-Clustered Indexes etc.,
Clustered Index -- Clustered Index will change the physical order of the table, it arrange records in sorted order on the column on which you defined clustered Index, hence we can define only ONE clustered index per table. It has one row in sys.partitions table with IndexId = 1. A cluster index can contain multiple columns hence we call it as composite index.
The database uses B-Tree structure to organize the indexes; it has different types of nodes.
1) Root Node - Always root node will be one, which contains pointers to other nodes.
2) Branch Nodes / Intermediate nodes – Two or more branch nodes, It contains pointers to other branch nodes or leaf nodes
3) Leaf Nodes - A leaf node contains index items and horizontal points to other leaf nodes.
Indexes are organized as B-Trees, Each page in an index B-Tree is called a index node. The root and intermediate pages contains index pages holding index rows. Each index row will contain a key value and a pointer to either an intermediate page or a data row in the leaf level of the index.
The leaf node of clustered index will contain actual data rows. While searching a clustered index field the query engine will fetch records very fast.
Clustered Index Considerations
These are particularly useful while using relational operators such as =,<>,>,<,between, exists etc.,
Also it gives good performance when you use order by and group by clauses.
While defining clustered indexed we need to choose a column in such a way that it should have
many distinct values and unique values.
Defining clustered index are not advised on column that are frequently updated, because update
potentially require re-ordering of the table data and it may cause page splits.
Non-Clustered Indexes
Like clustered index non-clustered index also follows B-Tree structure with few differences, the leaf node of non-clustered index doesn’t store data rows, and data is not stored in sorted order only index rows will be in sorted order. The leaf nodes of non-clustered index contain the non- clustered index key values and each key value has entry pointer to the data row that contains the key value. The pointer from index row in non-clustered index to data row is called row locator. A row locator structure is depends on whether it points to clustered index or to a heap. In simple words the data is stored in one place and index is stored in other place and will have pointers to the storage location of the data. Hence table can have more than one non-clustered index.
If the table is heap which doesn’t have clustered index the row locator points to the row.
If the table has clustered index then row locator refers to cluster index key.
Non-Clustered index has one row in sys.partitions table with IndexID>1
Prior to 2008 SQL Server can have 249 non clustered indexes per table and from 2008 onwards 999 clustered indexes can be created.
Unique constraint will create a non-clustered index by default.